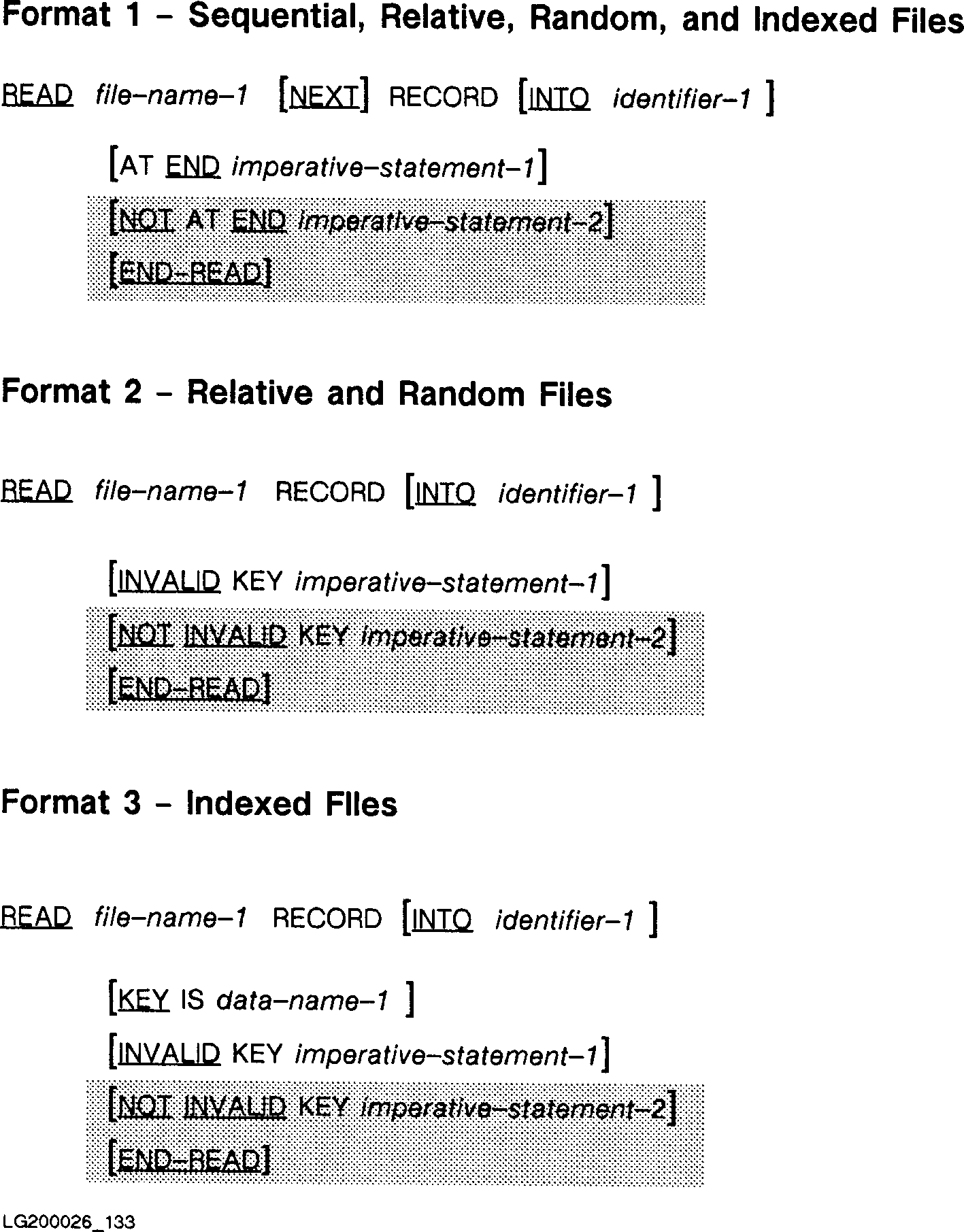
How To Read Cobol Data Files
UFSx(HWK)UFS-3 BOX SETUP REQURED FILE. 1# Download ufs(hwk) ufs-3 Setup exe file. UFSx(HWK)UFS-3 BOX SETUP METHOD. 1# Download all file unzip. 2# UFSUSBDriver30830W8 Instaill. 3# Extrack Phoenix like video. 4# Extrack SarasSoft like video. HWK Suite Setup + nokia + ufs panel 2.3.8; Picture Window theme. Powered by Blogger. Nokia ufs 3 setup. How to ufs-3 hwk box setup 2018 - install ufs3 panel latest version-hwk box not update. Latest UFS HWK Latest Version v2.3.0.7 Full Setup Free Download. Get ready to download UFS HWK Box Version v2.3.0.7 full setup whose latest version has been released and is ready for direct download from this official downloading link provided at the end of this page. UFS HWK Software is ready for free download.
.The file layout is defined positionally. There are nodelimiters or separators on which to base file parsing. The file maynot even have n characters at the end of eachrecord.They're usually encoded in EBCDIC, not ASCII orUnicode.They may include packed decimal fields; these are numericvalues represented with two decimal digits (or a decimal digit and asign) in each byte of the field.The first problem requires figuring the starting position and sizeof each field. In some cases, there are no gaps (or filler) betweenfields; in this case the sizes of each field are all that are required.Once we have the position and size, however, we can use a string sliceoperation to pick those characters out of a record. The code is simplyaLinestart:start+size.We can tackle the second problem using thecodecs module to decode the EBCDIC characters.The result of codecs.getdecoder('cp037') is a function thatyou can use as an EBCDIC decoder.The third problem requires that our program know the data type aswell as the position and offset of each field.
DataAccess can read indexed Cobol data files produced by these Cobols: MF, FSC, RM, ACU, and sequential Cobol files produced by any Cobol program.
If we know the data type,then we can do EBCDIC conversion or packed decimal conversion asappropriate. This is a much more subtle algorithm, since we have twostrategies for converting the data fields. See for some reasons why we'd do itthis way.In order to mirror COBOL's largely decimal world-view, we willneed to use the decimal module for all numbersand airthmetic.We note that the presence of packed decimal data changes the filefrom text to binary. We'll begin with techniques for handling a textfile with a fixed layout. However, since this often slides over tobinary file processing, we'll move on to that topic, also.Reading an All-Text File. If we ignore the EBCDIC and packed decimal problems, we caneasily process a fixed-layout file. The way to do this is to define ahandy structure that defines our record layout.
We can use thisstructure to parse each record, transforming the record from a stringinto a dictionary that we can use for further processing.In this example, we also use a generator function,yieldRecords, to break the file into individualrecords. We separate this functionality out so that our processing loopis a simple for statement, as it is with other kindsof files. In principle, this generator function can also check thelength of recBytes before it yields it.

If the blockof data isn't the expected size, the file was damaged and an exceptionshould be raised. Layout = ( 'field1', 0, 12 ),( 'field2', 12, 4 ),( 'anotherField', 16, 20 ),( 'lastField', 36, 8 ),reclen= 44def yieldRecords( aFile, recSize ):recBytes= aFile.read(recSize)while recBytes:yield recBytesrecBytes= aFile.read(recSize)cobolFile= file( 'my.cobol.file', 'rb' )for recBytes in yieldRecords(cobolFile, reclen):record = dictfor name, start, size in layout:recordname= recBytesstart:start+lenReading Mixed Data Types. If we have to tackle the complete EBCDIC and packed decimalproblem, we have to use a slightly more sophisticated structure forour file layout definition. First, we need some data conversionfunctions, then we can use those functions as part of picking apart arecord.We may need several conversion functions, depending on the kind ofdata that's present in our file. Minimally, we'll need the following twofunctions.
DisplayThis function is used to get character data. In COBOL, thisis called display data.
It will be in EBCDIC if our filesoriginated on a mainframe. PackedThis function is used to get packed decimal data. In COBOL,this is called 'comp-3' data. In our example, we have not dealtwith the insert of the decimal point prior to the creation of adecimal.Decimal object. Import codecsdisplay = codecs.getdecoder('cp037')def packed( bytes ):n= ' for b in bytes:-1:hi, lo = divmod( ord(b), 16 )n.append( str(hi) )n.append( str(lo) )digit, sign = divmod( ord(bytes-1), 16 )n.append( str(digit) )if sign in (0x0b, 0x0d ):n0= '-'else:n0= '+'return nGiven these two functions, we can expand our handy record layoutstructure. Layout = ( 'field1', 0, 12, display ),( 'field2', 12, 4, packed ),( 'anotherField', 16, 20, display ),( 'lastField', 36, 8, packed ),reclen= 44This changes our record decoding to the following. CobolFile= file( 'my.cobol.file', 'rb' )for recBytes in yieldRecords(cobolFile, reclen):record = dictfor name, start, size, convert in layout:recordname= convert( recBytesstart:start+len )This example underscores some of the key values of Python.
Simplethings can be kept simple. The layout structure, which describes thedata, is both easy to read, and written in Python itself. The evolutionof this example shows how adding a sophisticated feature can be donesimply and cleanly.At some point, our record layout will have to evolve from a simpletuple to a proper class definition. We'll need to take this evolutionarystep when we want to convert packed decimal numbers into values that wecan use for further processing.